Zexin Jane
I will continue to search, even if the endless stars make my search hopeless, even if I am alone.
Beijing Haidian, China
👋 Welcome! I am a Ph.D. Candidate in Computer Science at Institute of Computing Technology, Chinese Academy of Sciences (ICT, CAS), where I conduct research in the PL-System Research Group under the supervision of Dr. Huimin Cui and Dr. Chenxi Wang. Prior to that, I received my B.S. in Computer Science, from National University of Defense Technology (NUDT), , advised by Dr.Zengkun.
🤔 My research broadly covers computer architecture, compilers, heterogeneous computing, distributed systems, and deep learning. My current research interests include two main areas: (1) building system software using language models, and (2) creating scalable and cost-effective infrastructures for AI applications:
- Performant and cost-effective infrastructures for AI applications: I work to design and implement Deep Learning (DL) Compilers and frameworks to improve the performance and energy efficiency of emerging AI applications on heterogeneous computing platforms.
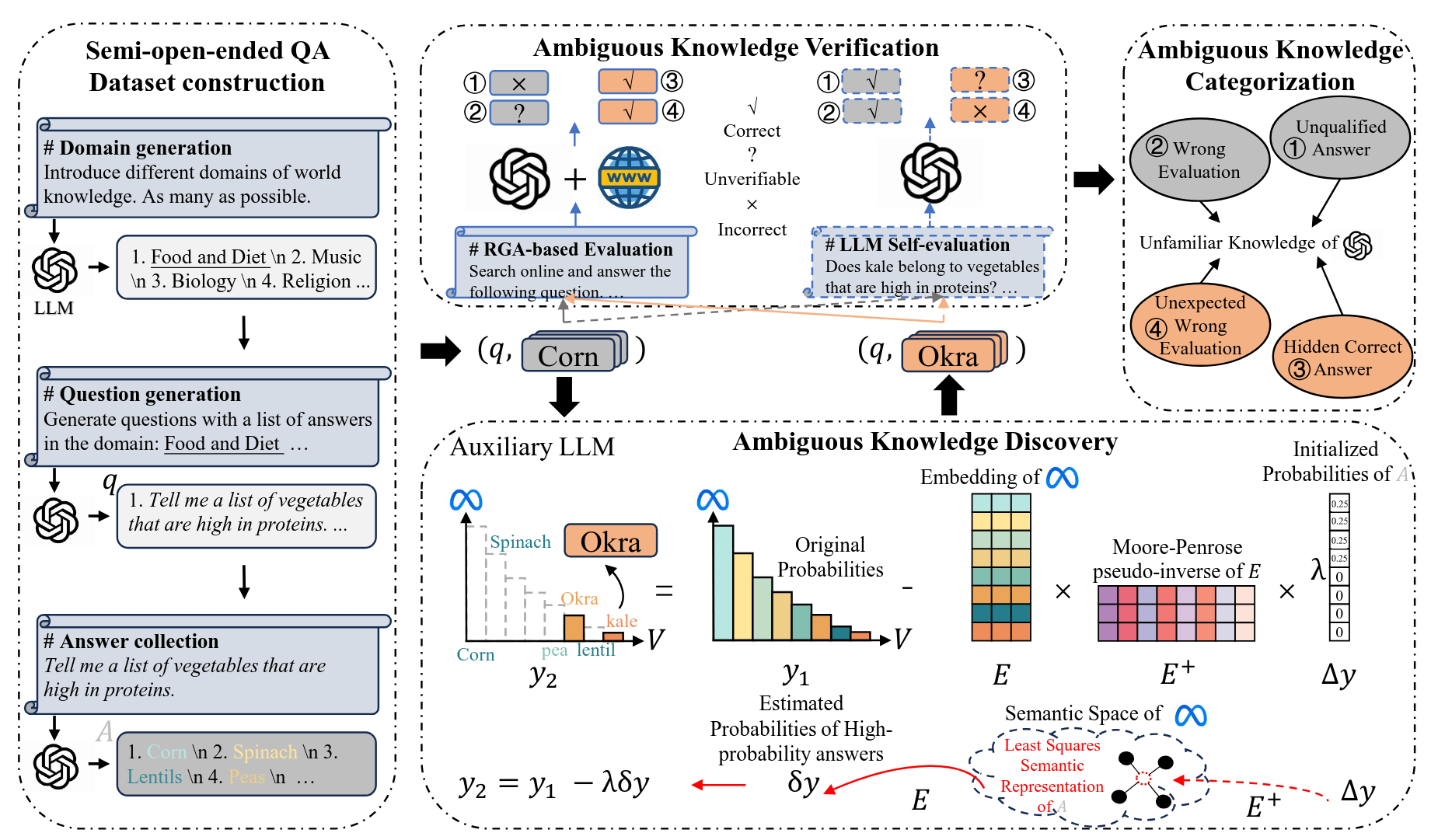
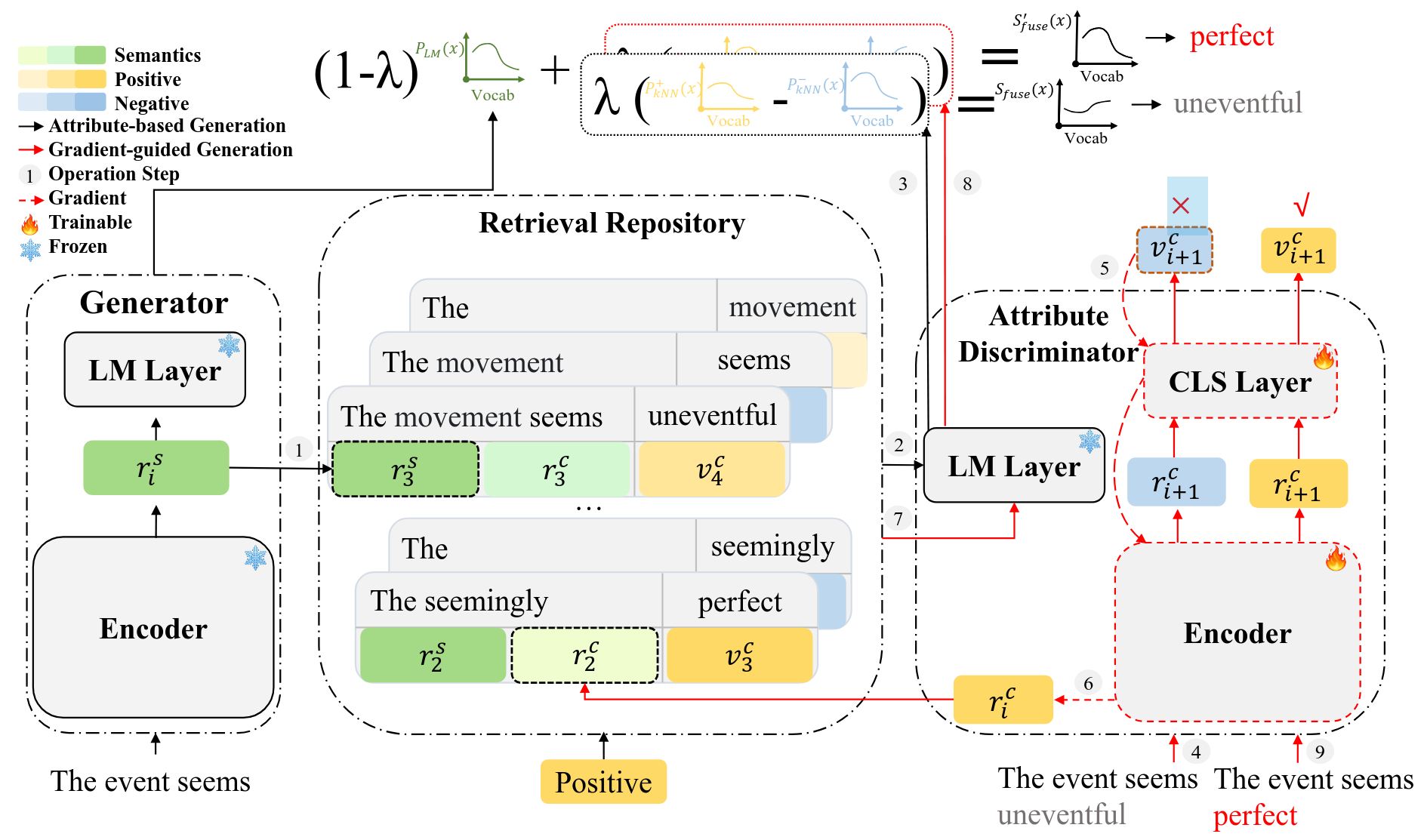
- LLM: CTG (ACL’23), Semi-Open-Ended QA (NIPS’24)
📫 If you are seeking any form of academic cooperation, please feel free to email me at zexinjian@gmail.com.
education

the Institute of Computing Technology, Chinese Academy of Sciences (ICT, CAS)
ph.D. in Computer Science
Sep.2025 - present
advised by Dr. Huimin Cui and Dr. Chenxi Wang

National University of Defense Technology (NUDT)
B.S. in Computer Science
Sep.2021 - Jul.2025
advised by Dr. Zengkun
experience

Advanced Institute of Information Technology (AIIT), Peking University
Research Intern
May.2025 - present
the Institute of Computing Technology, Chinese Academy of Sciences (ICT, CAS)
Visiting Student in Computer Science
Jun.2024 - Sep.2025
State Key Laboratory of High-Performance Computing (HPCL), NUDT
Research Intern
Sep.2022 - Seq.2024