publications
publications by categories in reversed chronological order.
2026
- ICSWorkshop26RV-IR: An MLIR-Based Architecture-Aware Intermediate Representation for Heterogeneous RISC-V AI AccelerationZexin Jian, Shuhui Jia, Chunwei Xia, and 2 more authorsIn Proceedings of the 2026 International Conference on Supercomputing Workshops, Belfast, United Kingdom, Jul 2026
"The growing interest in RISC-V-based AI accelerators creates an opportunity to build open and customizable machine learning systems, but it also exposes a compiler gap between generic tensor programs and accelerator-specific execution semantics. In practical heterogeneous CPU–NPU deployments, the compiler must reason about explicit memory spaces, accelerator invocation boundaries, asynchronous coordination, and software-managed data movement. Existing MLIR infrastructures provide strong support for high-level tensor optimization and progressive lowering, yet these generic abstractions do not always directly encode the architectural contracts needed by RISC-V AI backends. This paper presents RV-IR, an MLIR-based compilation framework centered on a RISC-V-oriented intermediate representation that serves as an architecture-aware layer between generic tensor dialects and backend-specific code generation. Rather than replacing existing MLIR dialects, RV-IR complements them by making accelerator-relevant concepts explicit, including custom compute operators, memory-space-aware allocation and transfer, hierarchical execution constructs, and synchronization points. The framework supports lowering from PyTorch through torch-mlir into RV-IR, and then into either a generic LLVM-oriented path or an accelerator-oriented path that interfaces with custom RISC-V runtime symbols and custom instruction stubs. We implement the proposed design in a research prototype based on torch-mlir. Experimental results on simulator-based RISC-V heterogeneous platforms demonstrate the effectiveness of our approach in enabling efficient execution of modern ML workloads."
@inproceedings{AICompiler-AI4HPCC26, title = {RV-IR: An MLIR-Based Architecture-Aware Intermediate Representation for Heterogeneous RISC-V AI Acceleration}, author = {Jian, Zexin and Jia, Shuhui and Xia, Chunwei and Wang, Di and Wang, Chenxi}, booktitle = {Proceedings of the 2026 International Conference on Supercomputing Workshops}, year = {2026}, month = jul, location = {Belfast, United Kingdom}, publisher = {ACM}, address = {New York, NY, USA}, numpages = {5}, doi = {10.1145/3774895.3812195}, url = {https://doi.org/10.1145/3774895.3812195}, }
2024
- NeurIPS24
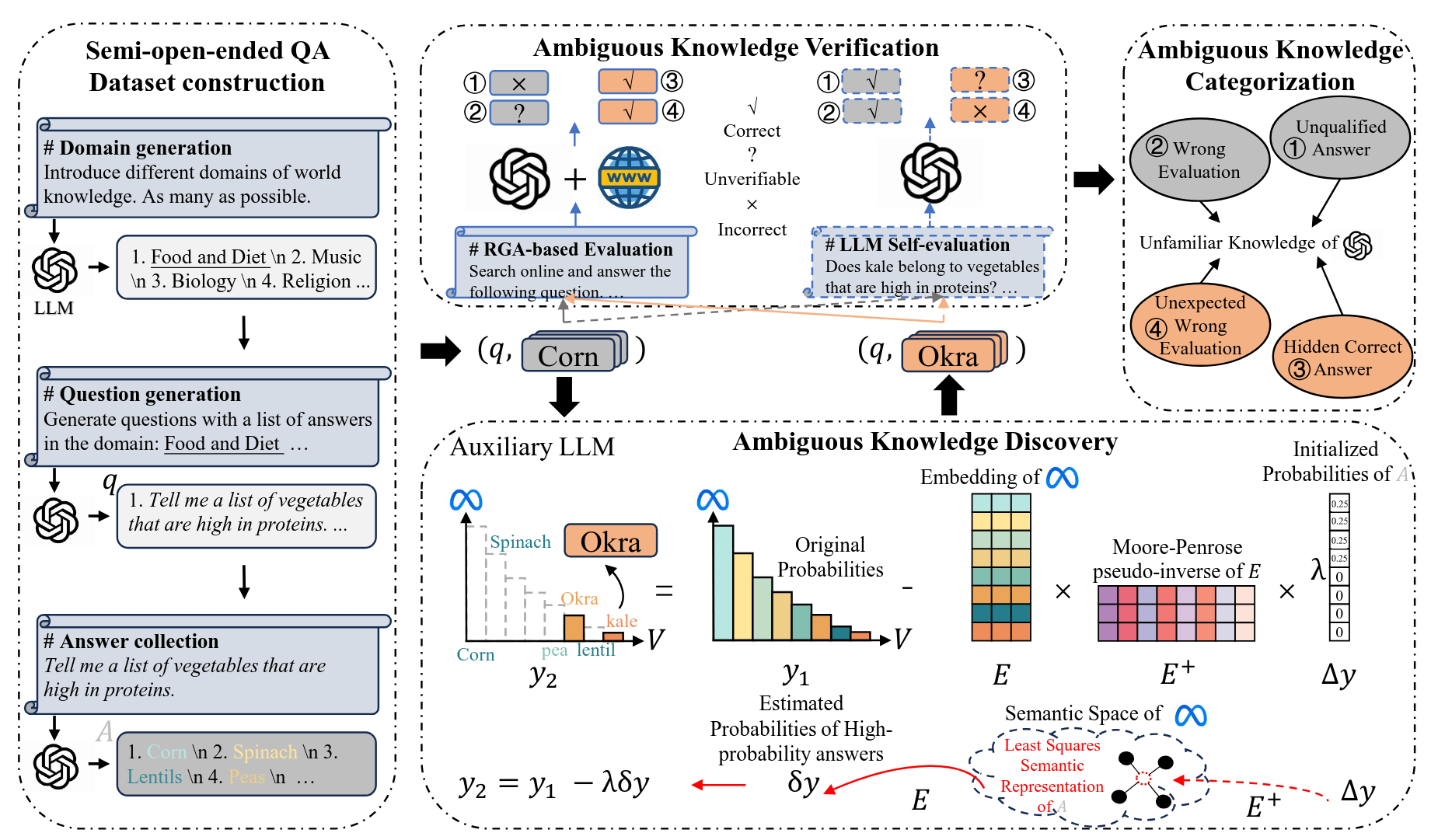 Perception of Knowledge Boundary for Large Language Models through Semi-open-ended Question AnsweringZhihua Wen, Zhiliang Tian, Zexin Jian, and 5 more authorsIn The Thirty-eighth Annual Conference on Neural Information Processing Systems, Jul 2024
Perception of Knowledge Boundary for Large Language Models through Semi-open-ended Question AnsweringZhihua Wen, Zhiliang Tian, Zexin Jian, and 5 more authorsIn The Thirty-eighth Annual Conference on Neural Information Processing Systems, Jul 2024"Large Language Models (LLMs) are widely used for knowledge-seeking purposes yet suffer from hallucinations. The knowledge boundary of an LLM limits its factual understanding, beyond which it may begin to hallucinate. Investigating the perception of LLMs’knowledge boundary is crucial for detecting hallucinations and LLMs’ reliable generation. Current studies perceive LLMs’ knowledge boundary on questions with a concrete answer (close-ended questions) while paying limited attention to semi-open-ended questions that correspond to many potential answers. Some researchers achieve it by judging whether the question is answerable or not. However, this paradigm is not so suitable for semi-open-ended questions, which are usually partially answerable questions containing both answerable answers and ambiguous (unanswerable) answers. Ambiguous answers are essential for knowledge-seeking, but they may go beyond the knowledge boundary of LLMs. In this paper, we perceive the LLMs’ knowledge boundary with semi-open-ended questions by discovering more ambiguous answers. First, we apply an LLM-based approach to construct semi-open-ended questions and obtain answers from a target LLM. Unfortunately, the output probabilities of mainstream black-box LLMs are inaccessible to sample for low-probability ambiguous answers. Therefore, we apply an open-sourced auxiliary model to explore ambiguous answers for the target LLM. We calculate the nearest semantic representation for existing answers to estimate their probabilities, with which we reduce the generation probability of high-probability existing answers to achieve a more effective generation. Finally, we compare the results from the RAG-based evaluation and LLM self-evaluation to categorize four types of ambiguous answers that are beyond the knowledge boundary of the target LLM. Following our method, we construct a dataset to perceive the knowledge boundary for GPT-4. We find that GPT-4 performs poorly on semi-open-ended questions and is often unaware of its knowledge boundary. Besides, our auxiliary model, LLaMA-2-13B, is effective in discovering many ambiguous answers, including correct answers neglected by GPT-4 and delusive wrong answers GPT-4 struggles to identify. "
@inproceedings{LLM-KnowledgeBoundary-NIPS24, title = {Perception of Knowledge Boundary for Large Language Models through Semi-open-ended Question Answering}, author = {Wen, Zhihua and Tian, Zhiliang and Jian, Zexin and Huang, Zhen and Ke, Pei and Gao, Yifu and Huang, Minlie and Li, Dongsheng}, booktitle = {The Thirty-eighth Annual Conference on Neural Information Processing Systems}, year = {2024}, }
2023
- ACL-finding23
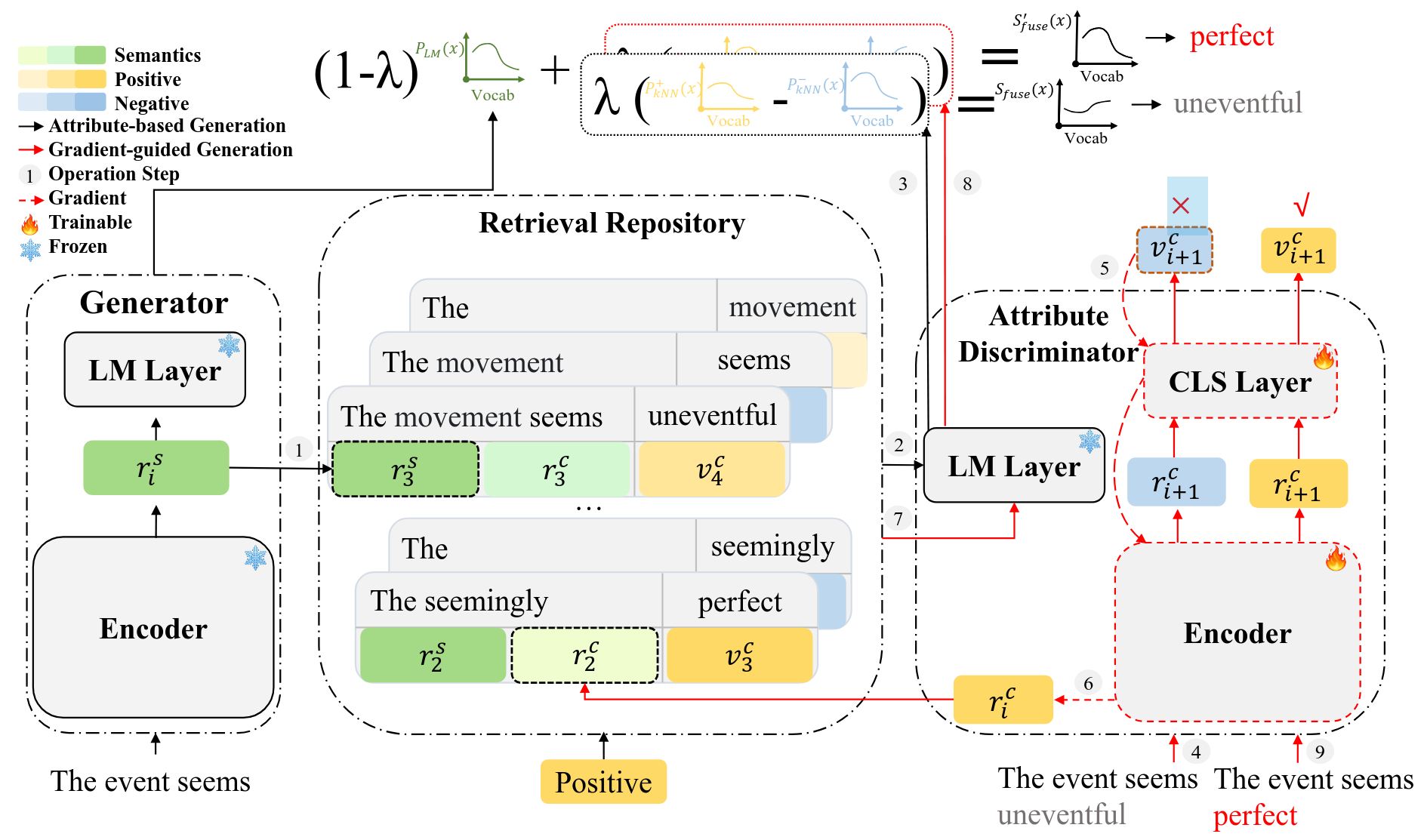 GRACE: gradient-guided controllable retrieval for augmenting attribute-based text generationZhihua Wen, Zhiliang Tian, Zhen Huang, and 4 more authorsIn Findings of the Association for Computational Linguistics: ACL 2023, Jul 2023
GRACE: gradient-guided controllable retrieval for augmenting attribute-based text generationZhihua Wen, Zhiliang Tian, Zhen Huang, and 4 more authorsIn Findings of the Association for Computational Linguistics: ACL 2023, Jul 2023"Attribute-based generation methods are of growing significance in controlling the generation of large pre-trained language models (PLMs). Existing studies control the generation by (1) finetuning the model with attributes or (2) guiding the inference processing toward control signals while freezing the PLM. However, finetuning approaches infuse domain bias into generation, making it hard to generate out-of-domain texts. Besides, many methods guide the inference in its word-by-word generation, pushing the word probability to the target attributes, resulting in less fluent sentences. We argue that distilling controlling information from natural texts can produce fluent sentences while maintaining high controllability. In this paper, we propose GRAdient-guided Controllable rEtrieval (GRACE), a retrieval-augmented generation framework to facilitate the generation of fluent sentences with high attribute relevance. GRACE memorizes the semantic and attribute information from unlabeled corpora and applies a controllable retrieval to obtain desired information. For the generation, we design techniques to eliminate the domain bias from the retrieval results and integrate it into the generation model. Additionally, we propose a gradient-guided generation scheme that iteratively steers generation toward higher attribute relevance. Experimental results and quantities of examples verify the effectiveness of our method."
@inproceedings{GRACE-ACL23, title = {GRACE: gradient-guided controllable retrieval for augmenting attribute-based text generation}, author = {Wen, Zhihua and Tian, Zhiliang and Huang, Zhen and Yang, Yuxin and Jian, Zexin and Wang, Changjian and Li, Dongsheng}, booktitle = {Findings of the Association for Computational Linguistics: ACL 2023}, month = jul, publisher = {"Association for Computational Linguistics"}, url = {"https://aclanthology.org/2023.findings-acl.530/"}, pages = {8377--8398}, year = {2023}, }